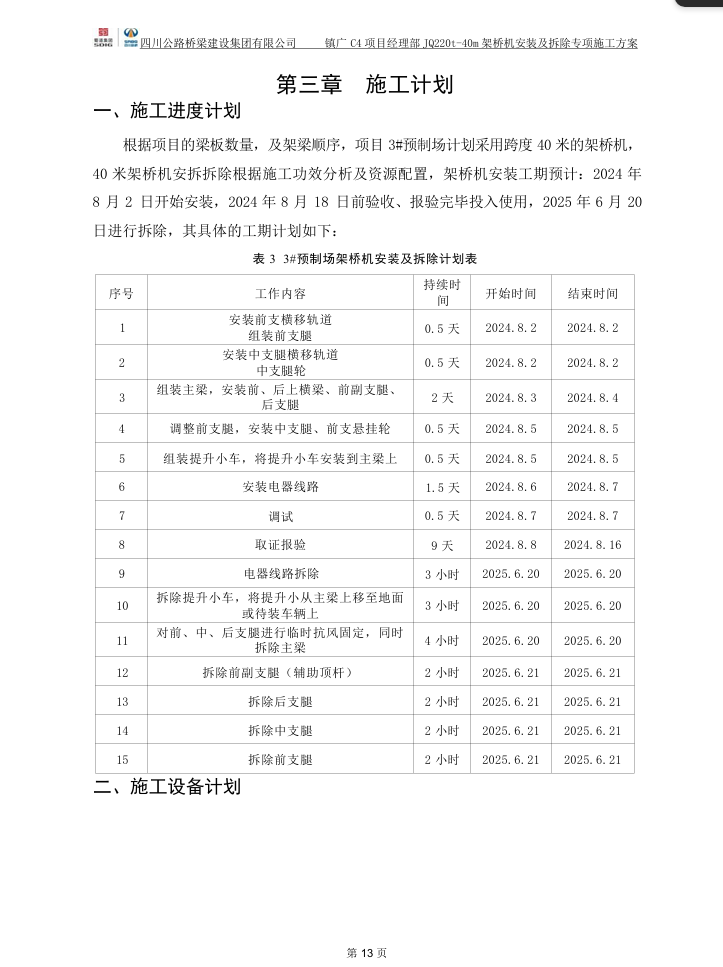
|
|
@@ -8,7 +8,7 @@ PDF 结构提取器。
|
|
|
|
|
|
import re
|
|
|
from dataclasses import dataclass
|
|
|
-from typing import Any, Dict, List, Optional, Tuple
|
|
|
+from typing import Any, Dict, List, Optional, Set, Tuple
|
|
|
|
|
|
import fitz
|
|
|
from foundation.observability.logger.loggering import review_logger as logger
|
|
|
@@ -144,27 +144,42 @@ class PdfStructureExtractor:
|
|
|
}
|
|
|
|
|
|
ocr_catalog: Optional[Dict[str, Any]] = None
|
|
|
- # if self.detect_toc:
|
|
|
- # try:
|
|
|
- # ocr_catalog = self._extract_catalog(file_content, progress_callback)
|
|
|
- # except Exception as exc:
|
|
|
- # logger.warning(f"[PDF提取] OCR目录提取失败: {exc}")
|
|
|
+ if self.detect_toc:
|
|
|
+ try:
|
|
|
+ ocr_catalog = self._extract_catalog(file_content, progress_callback)
|
|
|
+ if ocr_catalog:
|
|
|
+ ocr_catalog = self._normalize_catalog(ocr_catalog)
|
|
|
+ logger.info(f"[PDF提取] 目录提取完成: {ocr_catalog.get('total_chapters', 0)} 章")
|
|
|
+ except Exception as exc:
|
|
|
+ logger.warning(f"[PDF提取] OCR目录提取失败: {exc}")
|
|
|
|
|
|
doc = fitz.open(stream=file_content, filetype="pdf")
|
|
|
try:
|
|
|
- # 正文切分仍由 PyMuPDF 文本和标题规则驱动,OCR 只在切分后作为小节内容补充。
|
|
|
- body_lines = self._extract_body_lines(doc, progress_callback)
|
|
|
+ # OCR 必须在正文提取之前执行,以便在切分时原位替换表格区域的乱码文本。
|
|
|
ocr_results = self._extract_table_ocr_results(doc, progress_callback)
|
|
|
+ ocr_by_page: Dict[int, List[OcrResult]] = {}
|
|
|
+ ocr_success_count = 0
|
|
|
+ for r in ocr_results:
|
|
|
+ if r.success and str(r.text or "").strip():
|
|
|
+ ocr_by_page.setdefault(r.page_num, []).append(r)
|
|
|
+ ocr_success_count += 1
|
|
|
+
|
|
|
+ body_lines, ocr_inserted_count = self._extract_body_lines(doc, progress_callback, ocr_by_page)
|
|
|
raw_data, winning_rule, coverage_rate, rule_performance = self._extract_body_with_best_rule(body_lines)
|
|
|
chapters = self._convert_rule_output_to_chapters(raw_data)
|
|
|
- ocr_stats = self._insert_ocr_results_into_chapters(chapters, ocr_results)
|
|
|
body_catalog = self._build_body_catalog_from_chapters(chapters)
|
|
|
|
|
|
+ ocr_stats = {
|
|
|
+ "table_count": len(ocr_results),
|
|
|
+ "success_count": ocr_success_count,
|
|
|
+ "inserted_count": ocr_inserted_count,
|
|
|
+ }
|
|
|
+
|
|
|
result["chapters"] = chapters
|
|
|
result["total_pages"] = len(doc)
|
|
|
result["body_catalog"] = body_catalog
|
|
|
- #result["ocr_catalog"] = ocr_catalog
|
|
|
- result["catalog"] = body_catalog or ocr_catalog
|
|
|
+ result["ocr_catalog"] = ocr_catalog
|
|
|
+ result["catalog"] = ocr_catalog or body_catalog
|
|
|
result["body_rule"] = winning_rule
|
|
|
result["body_coverage"] = coverage_rate
|
|
|
result["rule_performance"] = rule_performance
|
|
|
@@ -197,28 +212,554 @@ class PdfStructureExtractor:
|
|
|
|
|
|
def _extract_catalog(self, file_content: bytes, progress_callback=None) -> Optional[Dict[str, Any]]:
|
|
|
"""
|
|
|
- 提取目录结构(YOLO检测 + OCR识别)
|
|
|
+ 提取目录结构(YOLO检测 + OCR识别),失败时兜底使用前几页纯文本解析。
|
|
|
|
|
|
Returns:
|
|
|
{"chapters": [...], "total_chapters": N} 或 None
|
|
|
"""
|
|
|
- from .toc_detector import TOCCatalogExtractor
|
|
|
-
|
|
|
- if self._toc_extractor is None:
|
|
|
- self._toc_extractor = TOCCatalogExtractor(
|
|
|
- model_path=self.toc_model_path,
|
|
|
- ocr_api_url=self.ocr_api_url,
|
|
|
- ocr_api_key=self.ocr_api_key,
|
|
|
- ocr_timeout=self.ocr_timeout,
|
|
|
+ catalog: Optional[Dict[str, Any]] = None
|
|
|
+
|
|
|
+ try:
|
|
|
+ from .toc_detector import TOCCatalogExtractor
|
|
|
+
|
|
|
+ if self._toc_extractor is None:
|
|
|
+ self._toc_extractor = TOCCatalogExtractor(
|
|
|
+ model_path=self.toc_model_path,
|
|
|
+ ocr_api_url=self.ocr_api_url,
|
|
|
+ ocr_api_key=self.ocr_api_key,
|
|
|
+ ocr_timeout=self.ocr_timeout,
|
|
|
+ )
|
|
|
+
|
|
|
+ catalog = self._toc_extractor.detect_and_extract(file_content, progress_callback)
|
|
|
+ except Exception as exc:
|
|
|
+ logger.warning(f"[PDF提取] 目录检测器不可用,回退到纯文本目录解析: {exc}")
|
|
|
+
|
|
|
+ if catalog:
|
|
|
+ catalog_chapters = self._sanitize_catalog_chapters(catalog.get("chapters", []))
|
|
|
+ raw_text = (catalog.get("raw_ocr_text") or "").strip()
|
|
|
+ if catalog_chapters or raw_text:
|
|
|
+ catalog.setdefault("source", "ocr_toc")
|
|
|
+ return catalog
|
|
|
+
|
|
|
+ fallback_catalog = self._extract_catalog_from_front_pages_text(file_content)
|
|
|
+ if fallback_catalog:
|
|
|
+ logger.info(
|
|
|
+ f"[PDF提取] 使用前几页纯文本目录兜底成功: {fallback_catalog.get('total_chapters', 0)} 章"
|
|
|
)
|
|
|
+ return fallback_catalog
|
|
|
|
|
|
- catalog = self._toc_extractor.detect_and_extract(file_content, progress_callback)
|
|
|
+ def _normalize_catalog(self, catalog: Dict[str, Any]) -> Dict[str, Any]:
|
|
|
+ """统一目录来源并择优合并。"""
|
|
|
if not catalog:
|
|
|
+ return {}
|
|
|
+
|
|
|
+ normalized = dict(catalog)
|
|
|
+ existing_chapters = self._sanitize_catalog_chapters(catalog.get("chapters", []))
|
|
|
+ raw_text = catalog.get("raw_ocr_text", "")
|
|
|
+ parsed_chapters = self._parse_catalog_from_raw_text(raw_text) if isinstance(raw_text, str) else []
|
|
|
+ selected_chapters = existing_chapters
|
|
|
+
|
|
|
+ if parsed_chapters:
|
|
|
+ if self._should_prefer_parsed_catalog(parsed_chapters, existing_chapters):
|
|
|
+ selected_chapters = parsed_chapters
|
|
|
+ elif existing_chapters:
|
|
|
+ logger.info(
|
|
|
+ "[PDF提取] raw_ocr_text目录解析结果异常,保留原始目录骨架: "
|
|
|
+ f"parsed={len(parsed_chapters)}, original={len(existing_chapters)}"
|
|
|
+ )
|
|
|
+ else:
|
|
|
+ selected_chapters = parsed_chapters
|
|
|
+
|
|
|
+ if selected_chapters:
|
|
|
+ selected_chapters = self._merge_catalog_chapters(
|
|
|
+ selected_chapters,
|
|
|
+ parsed_chapters,
|
|
|
+ )
|
|
|
+ normalized["chapters"] = selected_chapters
|
|
|
+ normalized["total_chapters"] = len(selected_chapters)
|
|
|
+ normalized["formatted_text"] = self._format_catalog_chapters(selected_chapters)
|
|
|
+ return normalized
|
|
|
+
|
|
|
+ def _parse_catalog_from_raw_text(self, text: str) -> List[Dict[str, Any]]:
|
|
|
+ """把目录页 OCR 原文解析成章节树。"""
|
|
|
+ if not text or not text.strip():
|
|
|
+ return []
|
|
|
+
|
|
|
+ chapters: List[Dict[str, Any]] = []
|
|
|
+ current_chapter: Optional[Dict[str, Any]] = None
|
|
|
+ active_l2_rule: Optional[str] = None
|
|
|
+ document_l1_rules: Optional[List[str]] = None
|
|
|
+
|
|
|
+ for raw_line in self._prepare_catalog_raw_lines(text):
|
|
|
+ title_text, page = self._split_catalog_entry(raw_line)
|
|
|
+ if not title_text:
|
|
|
+ continue
|
|
|
+
|
|
|
+ compact = re.sub(r"\s+", "", title_text)
|
|
|
+ if compact in {"目录", "目錄"}:
|
|
|
+ continue
|
|
|
+
|
|
|
+ chapter_matches = self._matching_rule_names(title_text, "l1", document_l1_rules)
|
|
|
+ if chapter_matches:
|
|
|
+ if document_l1_rules is None:
|
|
|
+ document_l1_rules = chapter_matches
|
|
|
+ current_chapter = {
|
|
|
+ "index": len(chapters) + 1,
|
|
|
+ "title": self._clean_chapter_title(title_text),
|
|
|
+ "page": str(page or 1),
|
|
|
+ "original": raw_line.strip(),
|
|
|
+ "subsections": [],
|
|
|
+ }
|
|
|
+ chapters.append(current_chapter)
|
|
|
+ active_l2_rule = None
|
|
|
+ continue
|
|
|
+
|
|
|
+ if current_chapter is None:
|
|
|
+ continue
|
|
|
+
|
|
|
+ section_matches = self._matching_rule_names(title_text, "l2")
|
|
|
+ if not section_matches:
|
|
|
+ numeric_section_title = self._coerce_numeric_catalog_section(
|
|
|
+ title_text,
|
|
|
+ document_l1_rules,
|
|
|
+ active_l2_rule,
|
|
|
+ )
|
|
|
+ if numeric_section_title:
|
|
|
+ section_key = self._normalize_heading_key(numeric_section_title)
|
|
|
+ existing_keys = {
|
|
|
+ self._normalize_heading_key(sub.get("title", ""))
|
|
|
+ for sub in current_chapter.get("subsections", [])
|
|
|
+ }
|
|
|
+ if section_key not in existing_keys:
|
|
|
+ current_chapter["subsections"].append({
|
|
|
+ "title": numeric_section_title,
|
|
|
+ "page": str(page or current_chapter.get("page", 1)),
|
|
|
+ "level": 2,
|
|
|
+ "original": raw_line.strip(),
|
|
|
+ })
|
|
|
+ continue
|
|
|
+
|
|
|
+ if active_l2_rule is None:
|
|
|
+ active_l2_rule = section_matches[0]
|
|
|
+ if active_l2_rule not in section_matches:
|
|
|
+ continue
|
|
|
+
|
|
|
+ section_title = self._clean_section_title(title_text)
|
|
|
+ section_key = self._normalize_heading_key(section_title)
|
|
|
+ existing_keys = {
|
|
|
+ self._normalize_heading_key(sub.get("title", ""))
|
|
|
+ for sub in current_chapter.get("subsections", [])
|
|
|
+ }
|
|
|
+ if section_key in existing_keys:
|
|
|
+ continue
|
|
|
+
|
|
|
+ current_chapter["subsections"].append({
|
|
|
+ "title": section_title,
|
|
|
+ "page": str(page or current_chapter.get("page", 1)),
|
|
|
+ "level": 2,
|
|
|
+ "original": raw_line.strip(),
|
|
|
+ })
|
|
|
+
|
|
|
+ return chapters
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _sanitize_catalog_chapters(cls, chapters: Any) -> List[Dict[str, Any]]:
|
|
|
+ if not isinstance(chapters, list):
|
|
|
+ return []
|
|
|
+
|
|
|
+ sanitized: List[Dict[str, Any]] = []
|
|
|
+ seen_chapter_keys: Set[str] = set()
|
|
|
+
|
|
|
+ for idx, chapter in enumerate(chapters, 1):
|
|
|
+ if not isinstance(chapter, dict):
|
|
|
+ continue
|
|
|
+
|
|
|
+ chapter_title = cls._clean_chapter_title(str(chapter.get("title", "") or ""))
|
|
|
+ chapter_key = cls._normalize_heading_key(chapter_title)
|
|
|
+ if not chapter_key or chapter_key in seen_chapter_keys:
|
|
|
+ continue
|
|
|
+
|
|
|
+ seen_chapter_keys.add(chapter_key)
|
|
|
+ chapter_page = str(chapter.get("page") or idx)
|
|
|
+ subsections: List[Dict[str, Any]] = []
|
|
|
+ seen_section_keys: Set[str] = set()
|
|
|
+
|
|
|
+ for subsection in chapter.get("subsections", []) or []:
|
|
|
+ if not isinstance(subsection, dict):
|
|
|
+ continue
|
|
|
+
|
|
|
+ section_title = cls._clean_section_title(str(subsection.get("title", "") or ""))
|
|
|
+ section_key = cls._normalize_heading_key(section_title)
|
|
|
+ if not section_key or section_key in seen_section_keys:
|
|
|
+ continue
|
|
|
+
|
|
|
+ seen_section_keys.add(section_key)
|
|
|
+ subsections.append({
|
|
|
+ "title": section_title,
|
|
|
+ "page": str(subsection.get("page") or chapter_page),
|
|
|
+ "level": 2,
|
|
|
+ "original": subsection.get("original", "") or section_title,
|
|
|
+ })
|
|
|
+
|
|
|
+ sanitized.append({
|
|
|
+ "index": len(sanitized) + 1,
|
|
|
+ "title": chapter_title,
|
|
|
+ "page": chapter_page,
|
|
|
+ "original": chapter.get("original", "") or chapter_title,
|
|
|
+ "subsections": subsections,
|
|
|
+ })
|
|
|
+
|
|
|
+ return sanitized
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _should_prefer_parsed_catalog(
|
|
|
+ cls,
|
|
|
+ parsed_chapters: List[Dict[str, Any]],
|
|
|
+ existing_chapters: List[Dict[str, Any]],
|
|
|
+ ) -> bool:
|
|
|
+ if not parsed_chapters:
|
|
|
+ return False
|
|
|
+
|
|
|
+ parsed_is_suspicious = cls._catalog_has_suspicious_structure(parsed_chapters)
|
|
|
+ existing_is_suspicious = cls._catalog_has_suspicious_structure(existing_chapters)
|
|
|
+
|
|
|
+ if parsed_is_suspicious:
|
|
|
+ if not existing_chapters or not existing_is_suspicious:
|
|
|
+ return False
|
|
|
+
|
|
|
+ parsed_score = cls._catalog_structure_score(parsed_chapters)
|
|
|
+ existing_score = cls._catalog_structure_score(existing_chapters)
|
|
|
+ overlap_ratio = cls._catalog_chapter_overlap_ratio(parsed_chapters, existing_chapters)
|
|
|
+ return overlap_ratio >= 0.6 and parsed_score > existing_score
|
|
|
+
|
|
|
+ if not existing_chapters:
|
|
|
+ return True
|
|
|
+
|
|
|
+ if existing_is_suspicious:
|
|
|
+ return True
|
|
|
+
|
|
|
+ if cls._should_prefer_single_level_parsed_catalog(parsed_chapters, existing_chapters):
|
|
|
+ return True
|
|
|
+
|
|
|
+ parsed_score = cls._catalog_structure_score(parsed_chapters)
|
|
|
+ existing_score = cls._catalog_structure_score(existing_chapters)
|
|
|
+ if parsed_score <= existing_score:
|
|
|
+ return False
|
|
|
+
|
|
|
+ if not cls._catalog_has_suspicious_structure(existing_chapters):
|
|
|
+ existing_count = len(existing_chapters)
|
|
|
+ parsed_count = len(parsed_chapters)
|
|
|
+ if parsed_count > max(existing_count * 2, existing_count + 8):
|
|
|
+ return False
|
|
|
+ if existing_count >= 4 and parsed_count < max(2, existing_count // 2):
|
|
|
+ return False
|
|
|
+
|
|
|
+ return True
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _should_prefer_single_level_parsed_catalog(
|
|
|
+ cls,
|
|
|
+ parsed_chapters: List[Dict[str, Any]],
|
|
|
+ existing_chapters: List[Dict[str, Any]],
|
|
|
+ ) -> bool:
|
|
|
+ """特判"单层目录被误识别成一章多节"的场景。"""
|
|
|
+ if len(parsed_chapters) < 2 or len(existing_chapters) != 1:
|
|
|
+ return False
|
|
|
+
|
|
|
+ if any(chapter.get("subsections") for chapter in parsed_chapters):
|
|
|
+ return False
|
|
|
+
|
|
|
+ existing_subsections = existing_chapters[0].get("subsections", []) or []
|
|
|
+ if len(existing_subsections) < len(parsed_chapters) - 1:
|
|
|
+ return False
|
|
|
+
|
|
|
+ parsed_pages = [
|
|
|
+ cls._safe_page_number(chapter.get("page"), 1)
|
|
|
+ for chapter in parsed_chapters
|
|
|
+ ]
|
|
|
+ return parsed_pages == sorted(parsed_pages)
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _catalog_has_suspicious_structure(cls, chapters: List[Dict[str, Any]]) -> bool:
|
|
|
+ if not chapters:
|
|
|
+ return False
|
|
|
+
|
|
|
+ titles = [(chapter.get("title", "") or "").strip() for chapter in chapters]
|
|
|
+ chinese_chapter_count = sum(
|
|
|
+ 1 for title in titles
|
|
|
+ if re.match(r"^第\s*(?:\d+|[一二三四五六七八九十百零两]+)\s*[章节部分篇]", title)
|
|
|
+ )
|
|
|
+ numeric_heading_count = sum(
|
|
|
+ 1 for title in titles
|
|
|
+ if re.match(r"^\d{1,2}(?:[\..。、])?\s+\S+", title)
|
|
|
+ )
|
|
|
+ embedded_numeric_body_count = 0
|
|
|
+ repeated_chapter_no_count = 0
|
|
|
+ reversed_chapter_no_count = 0
|
|
|
+ seen_chapter_numbers: Set[str] = set()
|
|
|
+ previous_numeric_chapter_no: Optional[int] = None
|
|
|
+
|
|
|
+ for title in titles:
|
|
|
+ chapter_match = re.match(
|
|
|
+ r"^第\s*(\d+|[一二三四五六七八九十百零两]+)\s*[章节部分篇]\s*(.*)$",
|
|
|
+ title,
|
|
|
+ )
|
|
|
+ if not chapter_match:
|
|
|
+ continue
|
|
|
+
|
|
|
+ chapter_no = re.sub(r"\s+", "", chapter_match.group(1))
|
|
|
+ chapter_body = (chapter_match.group(2) or "").strip()
|
|
|
+ if chapter_no in seen_chapter_numbers:
|
|
|
+ repeated_chapter_no_count += 1
|
|
|
+ seen_chapter_numbers.add(chapter_no)
|
|
|
+
|
|
|
+ if chapter_no.isdigit():
|
|
|
+ current_numeric_no = int(chapter_no)
|
|
|
+ if previous_numeric_chapter_no is not None and current_numeric_no < previous_numeric_chapter_no:
|
|
|
+ reversed_chapter_no_count += 1
|
|
|
+ previous_numeric_chapter_no = current_numeric_no
|
|
|
+
|
|
|
+ if re.match(r"^\d{1,2}(?:\.\d{1,2})*\.?(?:\s+|$)", chapter_body):
|
|
|
+ embedded_numeric_body_count += 1
|
|
|
+
|
|
|
+ if chinese_chapter_count >= 2 and numeric_heading_count >= max(3, chinese_chapter_count // 2):
|
|
|
+ return True
|
|
|
+
|
|
|
+ if chinese_chapter_count >= max(2, len(titles) // 3) and numeric_heading_count >= max(2, len(titles) // 6):
|
|
|
+ return True
|
|
|
+
|
|
|
+ if embedded_numeric_body_count >= max(2, len(titles) // 5):
|
|
|
+ return True
|
|
|
+
|
|
|
+ if repeated_chapter_no_count > 0 or reversed_chapter_no_count > 0:
|
|
|
+ return True
|
|
|
+
|
|
|
+ return False
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _catalog_structure_score(chapters: List[Dict[str, Any]]) -> int:
|
|
|
+ score = 0
|
|
|
+ for chapter in chapters:
|
|
|
+ score += 1
|
|
|
+ score += len(chapter.get("subsections", []) or [])
|
|
|
+ return score
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _catalog_chapter_overlap_ratio(
|
|
|
+ cls,
|
|
|
+ chapters_a: List[Dict[str, Any]],
|
|
|
+ chapters_b: List[Dict[str, Any]],
|
|
|
+ ) -> float:
|
|
|
+ if not chapters_a or not chapters_b:
|
|
|
+ return 0.0
|
|
|
+
|
|
|
+ keys_a = {
|
|
|
+ cls._catalog_chapter_identity_key(chapter.get("title", ""))
|
|
|
+ for chapter in chapters_a
|
|
|
+ if chapter.get("title")
|
|
|
+ }
|
|
|
+ keys_b = {
|
|
|
+ cls._catalog_chapter_identity_key(chapter.get("title", ""))
|
|
|
+ for chapter in chapters_b
|
|
|
+ if chapter.get("title")
|
|
|
+ }
|
|
|
+ if not keys_a or not keys_b:
|
|
|
+ return 0.0
|
|
|
+
|
|
|
+ return len(keys_a & keys_b) / max(1, min(len(keys_a), len(keys_b)))
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _merge_catalog_chapters(
|
|
|
+ cls,
|
|
|
+ base_chapters: List[Dict[str, Any]],
|
|
|
+ supplemental_chapters: List[Dict[str, Any]],
|
|
|
+ ) -> List[Dict[str, Any]]:
|
|
|
+ if not base_chapters:
|
|
|
+ return supplemental_chapters or []
|
|
|
+ if not supplemental_chapters:
|
|
|
+ return base_chapters
|
|
|
+
|
|
|
+ merged: List[Dict[str, Any]] = []
|
|
|
+ supplemental_by_key = {
|
|
|
+ cls._catalog_chapter_identity_key(chapter.get("title", "")): chapter
|
|
|
+ for chapter in supplemental_chapters
|
|
|
+ if chapter.get("title")
|
|
|
+ }
|
|
|
+
|
|
|
+ for index, chapter in enumerate(base_chapters, 1):
|
|
|
+ chapter_copy = {
|
|
|
+ **chapter,
|
|
|
+ "subsections": [dict(sub) for sub in chapter.get("subsections", []) or []],
|
|
|
+ }
|
|
|
+ chapter_key = cls._catalog_chapter_identity_key(chapter_copy.get("title", ""))
|
|
|
+ supplemental = supplemental_by_key.get(chapter_key)
|
|
|
+ if supplemental:
|
|
|
+ merged_subsections = cls._merge_catalog_subsections(
|
|
|
+ chapter_copy.get("subsections", []),
|
|
|
+ supplemental.get("subsections", []) or [],
|
|
|
+ )
|
|
|
+ chapter_copy["subsections"] = merged_subsections
|
|
|
+ chapter_copy["index"] = index
|
|
|
+ merged.append(chapter_copy)
|
|
|
+
|
|
|
+ return merged
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _merge_catalog_subsections(
|
|
|
+ cls,
|
|
|
+ base_subsections: List[Dict[str, Any]],
|
|
|
+ supplemental_subsections: List[Dict[str, Any]],
|
|
|
+ ) -> List[Dict[str, Any]]:
|
|
|
+ if not base_subsections:
|
|
|
+ return [dict(sub) for sub in supplemental_subsections]
|
|
|
+ if not supplemental_subsections:
|
|
|
+ return [dict(sub) for sub in base_subsections]
|
|
|
+
|
|
|
+ def _subsection_score(items: List[Dict[str, Any]]) -> int:
|
|
|
+ score = 0
|
|
|
+ for item in items:
|
|
|
+ title = (item.get("title", "") or "").strip()
|
|
|
+ if not title:
|
|
|
+ continue
|
|
|
+ score += 1
|
|
|
+ if re.match(r"^\d+\.\d+(?!\.\d)\.?\s*", title):
|
|
|
+ score += 3
|
|
|
+ elif re.match(r"^(第\s*[一二三四五六七八九十百零两]+\s*节)", title):
|
|
|
+ score += 3
|
|
|
+ elif re.match(r"^([一二三四五六七八九十百零两]+[、)\)\]])", title):
|
|
|
+ score += 3
|
|
|
+ elif re.match(r"^[【\[]\s*\d+\s*[\]】]", title):
|
|
|
+ score += 3
|
|
|
+ elif re.match(r"^\d{1,2}[\..。、]\s*", title):
|
|
|
+ score += 1
|
|
|
+ return score
|
|
|
+
|
|
|
+ base_score = _subsection_score(base_subsections)
|
|
|
+ supplemental_score = _subsection_score(supplemental_subsections)
|
|
|
+ if supplemental_score > base_score:
|
|
|
+ return [dict(sub) for sub in supplemental_subsections]
|
|
|
+
|
|
|
+ merged = [dict(sub) for sub in base_subsections]
|
|
|
+ seen_keys = {
|
|
|
+ cls._normalize_heading_key(sub.get("title", ""))
|
|
|
+ for sub in merged
|
|
|
+ if sub.get("title")
|
|
|
+ }
|
|
|
+ for subsection in supplemental_subsections:
|
|
|
+ subsection_key = cls._normalize_heading_key(subsection.get("title", ""))
|
|
|
+ if not subsection_key or subsection_key in seen_keys:
|
|
|
+ continue
|
|
|
+ merged.append(dict(subsection))
|
|
|
+ seen_keys.add(subsection_key)
|
|
|
+ return merged
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _coerce_numeric_catalog_section(
|
|
|
+ cls,
|
|
|
+ title_text: str,
|
|
|
+ document_l1_rules: Optional[List[str]],
|
|
|
+ active_l2_rule: Optional[str],
|
|
|
+ ) -> Optional[str]:
|
|
|
+ if active_l2_rule is not None:
|
|
|
return None
|
|
|
|
|
|
- normalized_catalog = dict(catalog)
|
|
|
- normalized_catalog.setdefault("source", "ocr_toc")
|
|
|
- return normalized_catalog
|
|
|
+ if not document_l1_rules:
|
|
|
+ return None
|
|
|
+
|
|
|
+ if "Rule_1_纯数字派" in document_l1_rules:
|
|
|
+ return None
|
|
|
+
|
|
|
+ if re.match(r"^\d{1,2}(?:[\..。、])?\s*(?!\d)[一-龥A-Za-z].*", title_text.strip()):
|
|
|
+ return cls._clean_section_title(title_text)
|
|
|
+
|
|
|
+ return None
|
|
|
+
|
|
|
+ def _extract_catalog_from_front_pages_text(
|
|
|
+ self,
|
|
|
+ file_content: bytes,
|
|
|
+ max_pages: int = 12,
|
|
|
+ ) -> Optional[Dict[str, Any]]:
|
|
|
+ """当目录检测失败时,从前几页纯文本中兜底解析目录。"""
|
|
|
+ doc = fitz.open(stream=file_content, filetype="pdf")
|
|
|
+ try:
|
|
|
+ catalog_pages: List[str] = []
|
|
|
+ started = False
|
|
|
+ scan_pages = min(max_pages, len(doc))
|
|
|
+
|
|
|
+ for page_num in range(scan_pages):
|
|
|
+ page = doc.load_page(page_num)
|
|
|
+ rect = page.rect
|
|
|
+ clip_box = fitz.Rect(0, self.clip_top, rect.width, rect.height - self.clip_bottom)
|
|
|
+ page_text = page.get_text("text", clip=clip_box)
|
|
|
+ if not page_text or not page_text.strip():
|
|
|
+ if started:
|
|
|
+ break
|
|
|
+ continue
|
|
|
+
|
|
|
+ has_marker, toc_like_count, page_suffix_count = self._catalog_text_signals(page_text)
|
|
|
+ if not started:
|
|
|
+ is_catalog_page = (
|
|
|
+ has_marker
|
|
|
+ or page_suffix_count >= 2
|
|
|
+ or (page_suffix_count >= 1 and toc_like_count >= 6)
|
|
|
+ )
|
|
|
+ if not is_catalog_page:
|
|
|
+ continue
|
|
|
+ started = True
|
|
|
+ else:
|
|
|
+ is_catalog_page = (
|
|
|
+ has_marker
|
|
|
+ or page_suffix_count >= 1
|
|
|
+ )
|
|
|
+ if not is_catalog_page:
|
|
|
+ break
|
|
|
+
|
|
|
+ catalog_pages.append(page_text)
|
|
|
+
|
|
|
+ raw_text = "\n".join(catalog_pages).strip()
|
|
|
+ if not raw_text:
|
|
|
+ return None
|
|
|
+
|
|
|
+ chapters = self._parse_catalog_from_raw_text(raw_text)
|
|
|
+ if not chapters:
|
|
|
+ return None
|
|
|
+
|
|
|
+ return {
|
|
|
+ "chapters": chapters,
|
|
|
+ "total_chapters": len(chapters),
|
|
|
+ "raw_ocr_text": raw_text,
|
|
|
+ "formatted_text": self._format_catalog_chapters(chapters),
|
|
|
+ "source": "front_pages_text",
|
|
|
+ }
|
|
|
+ finally:
|
|
|
+ doc.close()
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _catalog_text_signals(cls, text: str) -> Tuple[bool, int, int]:
|
|
|
+ compact_text = re.sub(r"\s+", "", text or "")
|
|
|
+ has_marker = "目录" in compact_text or "目錄" in compact_text
|
|
|
+ toc_like_count = 0
|
|
|
+ page_suffix_count = 0
|
|
|
+
|
|
|
+ for raw_line in cls._prepare_catalog_raw_lines(text):
|
|
|
+ title_text, page = cls._split_catalog_entry(raw_line)
|
|
|
+ if not title_text:
|
|
|
+ continue
|
|
|
+
|
|
|
+ compact_title = re.sub(r"\s+", "", title_text)
|
|
|
+ if compact_title in {"目录", "目錄"}:
|
|
|
+ toc_like_count += 1
|
|
|
+ continue
|
|
|
+
|
|
|
+ if page is not None:
|
|
|
+ page_suffix_count += 1
|
|
|
+ toc_like_count += 1
|
|
|
+ continue
|
|
|
+
|
|
|
+ if cls._matching_rule_names(title_text, "l1") or cls._matching_rule_names(title_text, "l2"):
|
|
|
+ toc_like_count += 1
|
|
|
+
|
|
|
+ return has_marker, toc_like_count, page_suffix_count
|
|
|
|
|
|
def _extract_table_ocr_results(self, doc: fitz.Document, progress_callback=None) -> List[OcrResult]:
|
|
|
"""在 OCR 启用时检测 PDF 表格区域,并发执行表格识别。"""
|
|
|
@@ -244,12 +785,13 @@ class PdfStructureExtractor:
|
|
|
clip_box = fitz.Rect(0, self.clip_top, rect.width, rect.height - self.clip_bottom)
|
|
|
regions = self.ocr_processor.detect_table_regions(page, page_index + 1, clip_box)
|
|
|
# 保存页面对象和区域坐标,便于 OcrProcessor 后续精确渲染表格裁剪区域。
|
|
|
- for bbox, score in regions:
|
|
|
+ for bbox, score, label in regions:
|
|
|
table_regions.append(TableRegion(
|
|
|
page_num=page_index + 1,
|
|
|
page=page,
|
|
|
bbox=bbox,
|
|
|
score=score,
|
|
|
+ label=label,
|
|
|
))
|
|
|
|
|
|
if page_index + 1 == total_pages or (page_index + 1) % 5 == 0:
|
|
|
@@ -272,100 +814,36 @@ class PdfStructureExtractor:
|
|
|
progress_callback=_progress_adapter,
|
|
|
)
|
|
|
|
|
|
- def _insert_ocr_results_into_chapters(
|
|
|
- self,
|
|
|
- chapters: Dict[str, Dict[str, Dict[str, Any]]],
|
|
|
- ocr_results: List[OcrResult],
|
|
|
- ) -> Dict[str, int]:
|
|
|
- """把成功识别的表格 OCR 文本追加到同页最可能的小节正文中。"""
|
|
|
-
|
|
|
- stats = {
|
|
|
- "table_count": len(ocr_results),
|
|
|
- "success_count": 0,
|
|
|
- "inserted_count": 0,
|
|
|
- }
|
|
|
- if not chapters or not ocr_results:
|
|
|
- return stats
|
|
|
-
|
|
|
- successful_results = [
|
|
|
- result for result in ocr_results
|
|
|
- if getattr(result, "success", False) and str(getattr(result, "text", "") or "").strip()
|
|
|
- ]
|
|
|
- stats["success_count"] = len(successful_results)
|
|
|
-
|
|
|
- for ocr_result in sorted(successful_results, key=lambda item: (item.page_num, item.bbox[1], item.bbox[0])):
|
|
|
- # 轻量提取器在切分后不再保留文本块坐标,因此使用页码范围作为 OCR 回填的稳定定位信号。
|
|
|
- target = self._find_ocr_target_section(chapters, ocr_result.page_num)
|
|
|
- if target is None:
|
|
|
- continue
|
|
|
-
|
|
|
- _, _, payload = target
|
|
|
- original_content = str(payload.get("content", "") or "").strip()
|
|
|
- if original_content == EMPTY_SECTION_PLACEHOLDER:
|
|
|
- original_content = ""
|
|
|
-
|
|
|
- ocr_text = str(ocr_result.text or "").strip()
|
|
|
- table_text = f"{TABLE_OCR_START}\n{ocr_text}\n{TABLE_OCR_END}"
|
|
|
- payload["content"] = f"{original_content}\n\n{table_text}".strip()
|
|
|
- payload["page_start"] = min(
|
|
|
- self._safe_page_number(payload.get("page_start"), ocr_result.page_num),
|
|
|
- ocr_result.page_num,
|
|
|
- )
|
|
|
- payload["page_end"] = max(
|
|
|
- self._safe_page_number(payload.get("page_end"), ocr_result.page_num),
|
|
|
- ocr_result.page_num,
|
|
|
- )
|
|
|
- stats["inserted_count"] += 1
|
|
|
-
|
|
|
- return stats
|
|
|
-
|
|
|
- def _find_ocr_target_section(
|
|
|
+ def _extract_body_lines(
|
|
|
self,
|
|
|
- chapters: Dict[str, Dict[str, Dict[str, Any]]],
|
|
|
- page_num: int,
|
|
|
- ) -> Optional[Tuple[str, str, Dict[str, Any]]]:
|
|
|
- """查找页码范围最能覆盖 OCR 表格所在页的小节。"""
|
|
|
-
|
|
|
- candidates: List[Tuple[int, int, str, str, Dict[str, Any]]] = []
|
|
|
- fallback: Optional[Tuple[str, str, Dict[str, Any]]] = None
|
|
|
-
|
|
|
- for chapter_title, sections in chapters.items():
|
|
|
- if not isinstance(sections, dict):
|
|
|
- continue
|
|
|
-
|
|
|
- for section_title, payload in sections.items():
|
|
|
- if not isinstance(payload, dict):
|
|
|
- continue
|
|
|
+ doc: fitz.Document,
|
|
|
+ progress_callback=None,
|
|
|
+ ocr_by_page: Dict[int, List[OcrResult]] = None,
|
|
|
+ ) -> Tuple[List[BodyLine], int]:
|
|
|
+ """读取页面正文文本,规范化正文行,并移除重复的非标题噪声。
|
|
|
|
|
|
- page_start = self._safe_page_number(payload.get("page_start"), page_num)
|
|
|
- page_end = self._safe_page_number(payload.get("page_end"), page_start)
|
|
|
- if section_title == SECTION_TITLE_KEY:
|
|
|
- if fallback is None and page_start <= page_num <= page_end:
|
|
|
- fallback = (chapter_title, section_title, payload)
|
|
|
- continue
|
|
|
-
|
|
|
- # 优先选择页码范围最窄的小节,过宽的范围通常是章节级内容外溢。
|
|
|
- if page_start <= page_num <= page_end:
|
|
|
- span = max(page_end - page_start, 0)
|
|
|
- candidates.append((span, -page_start, chapter_title, section_title, payload))
|
|
|
- elif page_start <= page_num:
|
|
|
- fallback = (chapter_title, section_title, payload)
|
|
|
+ Args:
|
|
|
+ ocr_by_page: 按页码分组的 OCR 结果,用于原位替换表格乱码文本。
|
|
|
|
|
|
- if candidates:
|
|
|
- _, _, chapter_title, section_title, payload = min(candidates, key=lambda item: (item[0], item[1]))
|
|
|
- return chapter_title, section_title, payload
|
|
|
- return fallback
|
|
|
-
|
|
|
- def _extract_body_lines(self, doc: fitz.Document, progress_callback=None) -> List[BodyLine]:
|
|
|
- """读取页面正文文本,规范化正文行,并移除重复的非标题噪声。"""
|
|
|
+ Returns:
|
|
|
+ (body_lines, ocr_inserted_count)
|
|
|
+ """
|
|
|
+ if ocr_by_page is None:
|
|
|
+ ocr_by_page = {}
|
|
|
|
|
|
page_lines_by_page: List[Tuple[int, List[str]]] = []
|
|
|
total_pages = len(doc)
|
|
|
repeated_margin_keys = self._find_repeated_margin_block_lines(doc)
|
|
|
+ ocr_inserted_count = 0
|
|
|
|
|
|
for page_index in range(total_pages):
|
|
|
page = doc.load_page(page_index)
|
|
|
- page_lines = self._extract_page_lines_with_margin_filter(page, repeated_margin_keys)
|
|
|
+ page_num = page_index + 1
|
|
|
+ page_ocr_results = ocr_by_page.get(page_num, [])
|
|
|
+ page_lines, page_inserted = self._extract_page_lines_with_margin_filter(
|
|
|
+ page, repeated_margin_keys, page_ocr_results,
|
|
|
+ )
|
|
|
+ ocr_inserted_count += page_inserted
|
|
|
|
|
|
recovered_headings, clipped_fragment_keys = self._recover_top_clipped_l1_headings(page, page_lines)
|
|
|
if clipped_fragment_keys:
|
|
|
@@ -377,19 +855,19 @@ class PdfStructureExtractor:
|
|
|
if recovered_headings:
|
|
|
page_lines = recovered_headings + page_lines
|
|
|
|
|
|
- page_lines_by_page.append((page_index + 1, page_lines))
|
|
|
+ page_lines_by_page.append((page_num, page_lines))
|
|
|
|
|
|
- if progress_callback and (page_index + 1 == total_pages or (page_index + 1) % 10 == 0):
|
|
|
+ if progress_callback and (page_num == total_pages or page_num % 10 == 0):
|
|
|
try:
|
|
|
progress_callback(
|
|
|
"正文抽取",
|
|
|
- int((page_index + 1) / max(total_pages, 1) * 60),
|
|
|
- f"读取正文页 {page_index + 1}/{total_pages}",
|
|
|
+ int(page_num / max(total_pages, 1) * 60),
|
|
|
+ f"读取正文页 {page_num}/{total_pages}",
|
|
|
)
|
|
|
except Exception:
|
|
|
pass
|
|
|
|
|
|
- # 页眉页脚往往跨页重复,但真实标题不能被误删,所以只移除“不像标题”的重复行。
|
|
|
+ # 页眉页脚往往跨页重复,但真实标题不能被误删,所以只移除"不像标题"的重复行。
|
|
|
repeated_noise_keys = self._find_repeated_non_heading_lines(page_lines_by_page, total_pages)
|
|
|
body_lines: List[BodyLine] = []
|
|
|
for page, lines in page_lines_by_page:
|
|
|
@@ -397,29 +875,35 @@ class PdfStructureExtractor:
|
|
|
if self._normalize_repeated_line_key(line) in repeated_noise_keys:
|
|
|
continue
|
|
|
body_lines.append(BodyLine(page=page, text=line))
|
|
|
- return body_lines
|
|
|
+ return body_lines, ocr_inserted_count
|
|
|
|
|
|
def _extract_page_lines_with_margin_filter(
|
|
|
self,
|
|
|
page: fitz.Page,
|
|
|
repeated_margin_keys: set[str],
|
|
|
- ) -> List[str]:
|
|
|
- """按文本块读取页面,并过滤跨页重复的页边页眉/页脚行。"""
|
|
|
+ ocr_results_for_page: List[OcrResult] = None,
|
|
|
+ ) -> Tuple[List[str], int]:
|
|
|
+ """按文本块读取页面,过滤页眉页脚,并原位替换表格区域的 OCR 文本。
|
|
|
|
|
|
+ Returns:
|
|
|
+ (page_lines, ocr_inserted_count)
|
|
|
+ """
|
|
|
rect = page.rect
|
|
|
body_top = self.clip_top
|
|
|
body_bottom = rect.height - self.clip_bottom
|
|
|
+ ocr_results_for_page = ocr_results_for_page or []
|
|
|
|
|
|
try:
|
|
|
page_dict = page.get_text("dict")
|
|
|
except Exception:
|
|
|
clip_box = fitz.Rect(0, body_top, rect.width, body_bottom)
|
|
|
text = page.get_text("text", clip=clip_box)
|
|
|
- return [
|
|
|
+ lines = [
|
|
|
stripped
|
|
|
for stripped in (line.strip() for line in self._prepare_page_lines(text))
|
|
|
if stripped and not self._is_header_footer(stripped)
|
|
|
]
|
|
|
+ return lines, 0
|
|
|
|
|
|
page_lines: List[str] = []
|
|
|
blocks = sorted(
|
|
|
@@ -429,7 +913,39 @@ class PdfStructureExtractor:
|
|
|
item.get("bbox", [0, 0, 0, 0])[0],
|
|
|
),
|
|
|
)
|
|
|
- for block in blocks:
|
|
|
+
|
|
|
+ # 预计算每个 block 匹配到的 OCR 结果索引
|
|
|
+ ocr_match_by_block: Dict[int, int] = {}
|
|
|
+ ocr_used: Set[int] = set()
|
|
|
+
|
|
|
+ if ocr_results_for_page:
|
|
|
+ for block_idx, block in enumerate(blocks):
|
|
|
+ bbox = block.get("bbox") or ()
|
|
|
+ if len(bbox) != 4:
|
|
|
+ continue
|
|
|
+ _, y0, _, y1 = bbox
|
|
|
+ if y1 <= body_top or y0 >= body_bottom:
|
|
|
+ continue
|
|
|
+
|
|
|
+ block_text = self._extract_text_block_text(block)
|
|
|
+ if not block_text or self._matches_any_heading(block_text):
|
|
|
+ continue
|
|
|
+
|
|
|
+ bx0, by0, bx1, by1 = bbox
|
|
|
+ for ocr_idx, ocr_result in enumerate(ocr_results_for_page):
|
|
|
+ if ocr_idx in ocr_used:
|
|
|
+ continue
|
|
|
+ rx0, ry0, rx1, ry1 = ocr_result.bbox
|
|
|
+ overlap_x = max(0, min(bx1, rx1) - max(bx0, rx0))
|
|
|
+ overlap_y = max(0, min(by1, ry1) - max(by0, ry0))
|
|
|
+ overlap_area = overlap_x * overlap_y
|
|
|
+ block_area = max((bx1 - bx0) * (by1 - by0), 1)
|
|
|
+ if overlap_area / block_area > 0.5:
|
|
|
+ ocr_match_by_block[block_idx] = ocr_idx
|
|
|
+ ocr_used.add(ocr_idx)
|
|
|
+ break
|
|
|
+
|
|
|
+ for block_idx, block in enumerate(blocks):
|
|
|
bbox = block.get("bbox") or ()
|
|
|
if len(bbox) != 4:
|
|
|
continue
|
|
|
@@ -438,19 +954,27 @@ class PdfStructureExtractor:
|
|
|
if y1 <= body_top or y0 >= body_bottom:
|
|
|
continue
|
|
|
|
|
|
- block_text = self._extract_text_block_text(block)
|
|
|
- if not block_text:
|
|
|
+ in_margin = self._is_margin_band(y0, y1, rect.height)
|
|
|
+
|
|
|
+ if block_idx in ocr_match_by_block:
|
|
|
+ ocr_result = ocr_results_for_page[ocr_match_by_block[block_idx]]
|
|
|
+ ocr_text = str(ocr_result.text or "").strip()
|
|
|
+ source_text = f"{TABLE_OCR_START}\n{ocr_text}\n{TABLE_OCR_END}"
|
|
|
+ else:
|
|
|
+ source_text = self._extract_text_block_text(block)
|
|
|
+
|
|
|
+ if not source_text:
|
|
|
continue
|
|
|
|
|
|
- in_margin = self._is_margin_band(y0, y1, rect.height)
|
|
|
- for line in self._prepare_page_lines(block_text):
|
|
|
+ for line in self._prepare_page_lines(source_text):
|
|
|
stripped = line.strip()
|
|
|
if not stripped or self._is_header_footer(stripped):
|
|
|
continue
|
|
|
if in_margin and self._is_repeated_margin_noise(stripped, repeated_margin_keys):
|
|
|
continue
|
|
|
page_lines.append(stripped)
|
|
|
- return page_lines
|
|
|
+
|
|
|
+ return page_lines, len(ocr_match_by_block)
|
|
|
|
|
|
def _find_repeated_margin_block_lines(self, doc: fitz.Document) -> set[str]:
|
|
|
"""统计顶部/底部页边区域中跨页重复出现、且不像标题的文本行。"""
|
|
|
@@ -766,7 +1290,7 @@ class PdfStructureExtractor:
|
|
|
}
|
|
|
|
|
|
for index, item in enumerate(body_lines):
|
|
|
- # 先处理跨行标题碎片,再进入章/节识别,避免“第X章”单独成行时丢标题。
|
|
|
+ # 先处理跨行标题碎片,再进入章/节识别,避免"第X章"单独成行时丢标题。
|
|
|
original_line = item.text.strip()
|
|
|
page = item.page
|
|
|
if not original_line or original_line.isdigit():
|
|
|
@@ -997,7 +1521,7 @@ class PdfStructureExtractor:
|
|
|
|
|
|
@classmethod
|
|
|
def _has_stable_explicit_chapter_headings(cls, body_lines: List[BodyLine]) -> bool:
|
|
|
- """判断正文前段是否已经存在稳定的“第X章”显式章节结构。"""
|
|
|
+ """判断正文前段是否已经存在稳定的"第X章"显式章节结构。"""
|
|
|
|
|
|
chapter_numbers: List[int] = []
|
|
|
|
|
|
@@ -1057,7 +1581,7 @@ class PdfStructureExtractor:
|
|
|
|
|
|
@classmethod
|
|
|
def _detect_cn_order_l2_style(cls, line: str) -> Optional[str]:
|
|
|
- """识别中文序号小节标题的样式,区分“ 一)”和“ 一、/一 空格”。"""
|
|
|
+ """识别中文序号小节标题的样式,区分" 一)"和" 一、/一 空格"。"""
|
|
|
|
|
|
cleaned = cls._strip_catalog_page_suffix(line)
|
|
|
cleaned = re.sub(r"\s+", " ", str(cleaned or "").strip())
|
|
|
@@ -1387,6 +1911,108 @@ class PdfStructureExtractor:
|
|
|
|
|
|
return re.sub(r"\s+", "", str(line or "").strip())
|
|
|
|
|
|
+ @staticmethod
|
|
|
+ def _normalize_heading_key(text: str) -> str:
|
|
|
+ normalized = PdfStructureExtractor._strip_catalog_page_suffix((text or "").strip())
|
|
|
+ normalized = normalized.replace("【", "[").replace("】", "]")
|
|
|
+ normalized = normalized.replace("(", "(").replace(")", ")")
|
|
|
+ normalized = normalized.replace(".", ".").replace("。", ".")
|
|
|
+ normalized = re.sub(r"\s+", "", normalized)
|
|
|
+ return normalized
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _matching_rule_names(
|
|
|
+ cls,
|
|
|
+ line: str,
|
|
|
+ level: str,
|
|
|
+ rule_names: Optional[List[str]] = None,
|
|
|
+ ) -> List[str]:
|
|
|
+ clean_line = line.strip()
|
|
|
+ if level == "l1":
|
|
|
+ clean_line = cls._strip_leading_page_number_from_heading(clean_line)
|
|
|
+ names = rule_names or list(cls.RULE_LIB.keys())
|
|
|
+ return [
|
|
|
+ rule_name
|
|
|
+ for rule_name in names
|
|
|
+ if cls.RULE_LIB[rule_name][level].match(clean_line)
|
|
|
+ ]
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _split_catalog_entry(line: str) -> Tuple[str, Optional[int]]:
|
|
|
+ cleaned = line.strip()
|
|
|
+ if not cleaned:
|
|
|
+ return "", None
|
|
|
+
|
|
|
+ cleaned = re.sub(r"\s+", " ", cleaned).strip()
|
|
|
+ page_match = re.search(
|
|
|
+ r"(?:[.…·•·• ]{2,})[-–— ]*(\d+)\s*[-–— ]*$",
|
|
|
+ cleaned,
|
|
|
+ )
|
|
|
+ if page_match:
|
|
|
+ title_text = cleaned[:page_match.start()].strip()
|
|
|
+ title_text = re.sub(r"[.…·• ]+$", "", title_text).strip()
|
|
|
+ return title_text, int(page_match.group(1))
|
|
|
+
|
|
|
+ return cleaned, None
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _prepare_catalog_raw_lines(cls, text: str) -> List[str]:
|
|
|
+ raw_lines = [line.strip() for line in text.splitlines() if line.strip()]
|
|
|
+ prepared: List[str] = []
|
|
|
+ index = 0
|
|
|
+
|
|
|
+ while index < len(raw_lines):
|
|
|
+ current = raw_lines[index].strip()
|
|
|
+ compact_current = re.sub(r"\s+", "", current)
|
|
|
+
|
|
|
+ if compact_current in {"目", "錄", "录"} and index + 1 < len(raw_lines):
|
|
|
+ next_compact = re.sub(r"\s+", "", raw_lines[index + 1].strip())
|
|
|
+ if compact_current + next_compact in {"目录", "目錄"}:
|
|
|
+ prepared.append(compact_current + next_compact)
|
|
|
+ index += 2
|
|
|
+ continue
|
|
|
+
|
|
|
+ if cls._is_incomplete_heading_fragment(current) and index + 1 < len(raw_lines):
|
|
|
+ next_line = raw_lines[index + 1].strip()
|
|
|
+ candidate = f"{current} {next_line}".strip()
|
|
|
+ _, candidate_page = cls._split_catalog_entry(candidate)
|
|
|
+ if (
|
|
|
+ cls._matching_rule_names(candidate, "l1")
|
|
|
+ or cls._matching_rule_names(candidate, "l2")
|
|
|
+ or candidate_page is not None
|
|
|
+ ):
|
|
|
+ prepared.append(candidate)
|
|
|
+ index += 2
|
|
|
+ continue
|
|
|
+
|
|
|
+ prepared.append(current)
|
|
|
+ index += 1
|
|
|
+
|
|
|
+ return prepared
|
|
|
+
|
|
|
+ @classmethod
|
|
|
+ def _catalog_chapter_identity_key(cls, title: str) -> str:
|
|
|
+ cleaned = cls._clean_chapter_title(title)
|
|
|
+ if not cleaned:
|
|
|
+ return ""
|
|
|
+
|
|
|
+ chapter_match = re.match(
|
|
|
+ r"^第\s*(?:\d+|[一二三四五六七八九十百零两]+)\s*[章节部部分篇]\s*(.*)$",
|
|
|
+ cleaned,
|
|
|
+ )
|
|
|
+ if chapter_match:
|
|
|
+ chapter_body = cls._normalize_heading_key(chapter_match.group(1))
|
|
|
+ if chapter_body:
|
|
|
+ return chapter_body
|
|
|
+
|
|
|
+ numeric_match = re.match(r"^\d{1,2}(?:[\..。、])?\s*(.*)$", cleaned)
|
|
|
+ if numeric_match:
|
|
|
+ numeric_body = cls._normalize_heading_key(numeric_match.group(1))
|
|
|
+ if numeric_body:
|
|
|
+ return numeric_body
|
|
|
+
|
|
|
+ return cls._normalize_heading_key(cleaned)
|
|
|
+
|
|
|
@classmethod
|
|
|
def _matches_any_heading(cls, line: str) -> bool:
|
|
|
"""判断文本是否命中任意一套章/节标题规则。"""
|


{kind=link}
{kind=link}